





1.近百年、50年基础数据集的质量控制、均一性研究
1.1 站点资料概况
原始数据来自与国家气象信息中心气象资料室收集整理的中国大陆地区1900年1月-2009年12月的所有气象观测站(1951年以后为国家基本、基准站点)的逐月降水量数据。另外,我们尝试引入美国NOAA研制的全球历史气候网数据集(Global Historical Climatology Network, monthly version2,经过了质量控制和均一性订正)中中国范围内的作为补充。但分析表明,GHCN数据集中的台站基本与我们收集到的台站重叠,但GHCN某些台站的降水资料更完整;因此,我们将这些台站的降水资料引入以充实原有降水资料。另外,从GHCN中获得的香港站的降水资料也被用于后续分析中。
逐日尺度降水质量控制包括:气候界限值检验和空间一致性检查;逐月降水量质量控制包括:极值检验、时间域检验、空间域检验。方法均采用目前国际上较为成熟的方法。
台站数量的变化情况见图1,如图,1930年之前台站数量在100个以下,30年代至40年代中期台站数量在100~200个之间,40年代中期至50年代初期台站数量又回落至100个以下,此后台站数量激增,1960年之后台站数量基本维持在700个左右。图2分别给出了解放前的台站分布和所有台站的分布。如图所示,解放前西部台站很少,而这个问题在建国后基本得到解决。

图1 1900-2009年台站数逐年变化曲线
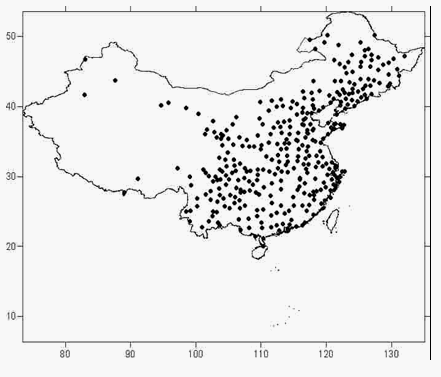

图2 观测台站的地理分布
(上图:1900-1950年有一年以上观测资料的台站 下图:所有台站)
1.2 降水资料均一性检验、订正
从每个待检站临近的所有台站中挑选4个与待检站序列相关系数最高的年

下一步对该序列进行标准化,标准化的目的是使得序列的值在1附近波动(如果是差值则在0附近波动),并且近似服从N (0,1)分布。即:
![]() (3)
(3)
SNHT方法目前已经有很多版本,可以针对不同的要素和实际情况采用不同的版本,各种版本各有优势,根据降水序列的实际情况,经过比较,采用单不连续点的平均值检验的效果较好。至于两个以上不连续点的检验则通过分段来进行检验。
对序列{Zi}(i=1,2,……,n)这样假设为:
如果{Zi}序列没有不连续点存在,则统计假设为:H0:对于任意i,Zi ∈N(0,1)
如果{Zi}有一个不连续点a,则统计假设为:
Zi ∈N(μ1,1) i ∈{1,…,a}
Zi ∈N(μ2,1) i ∈{a+1,…,n} (4)
μ1,μ2分别为假设不连续点a前后两个序列的平均值(μ1≠μ2),n为样本容量。σ为前后两段的均方差,因为没有考虑方差间断,所以前后不变。根据最大似然比率的标准技术(Lindgren,1968)〔18〕,经过一定的近似处理,构造统计量Ts作为显著性判据:

![]()
订正后的序列,在应用了上述订正系数后,序列就可以认为是均一的。对于月值的订正,则根据各月逐年待检序列和参考序列的差值的线性关系将该补偿值应用到各月序列中,得出逐月订正值。
2. 不同尺度、分辨率网格数据集的研制
区域以及全球尺度的高密度气象数据,是气候变化和生态系统研究中所需的重要数据。但是由于研究区特殊的地理位置以及气象观测仪器设备的不足,使得获取一定区域的实测数据存在困难。在研究全球或区域大尺度气候变化序列时,往往需要先将气候序列网格化,以确保网格序列能代表相同面积上的气候变化,从而有效减小或避免空间采样误差。因此,研究者往往需要借助一定的空间分析技术,实现对气象要素的空间插值。
基于质量控制和均一化后的降水量观测数据,制作中国区域近百年网格降水量数据集。鉴于解放前西北内陆区的实际台站分布非常稀疏,因此课题组将研制两套不同时空分辨率的中国降水量数据集,第一套是中国5°×5°的逐月网格降水量数据集,时间范围从1901年——2007年,简称MON_5°;第二套是中国0.5°×0.5°的逐日网格降水量数据集,时间范围从1957年——2007年,简称DAY_0.5°。
2.1 中国5°×5°的逐月网格降水量数据集
5°×5°的逐月网格降水量数据集采用反距离加权平均的方法。 反距离加权法又名空间滑动平均法,它是根据近邻点的平均值估计未知点的方法,该方法基于地理学第一定律——相似相近原理,即根据样本点周围数值随着其到样本点距离的变化而变化,并且呈现反相关,距离样本点越近,其数值和样本点的数值越近。可表示为
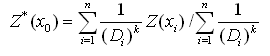 (7)
(7)

显著影响着插值的结果,这里取k = 1进行插值.
2.2 中国0.5°×0.5°的逐日网格降水量数据集。
针对全国日降水量气候观测值,对该数据进行傅立叶变换剔除高频噪声,得到台站降水量的日气候值。这里选取Shepard空间插值方法对降水量日气候值进行2维(经度和纬度)空间插值,得到日气候值的分析场资料,该资料的空间分辨率为0.05°×0.05°。Shepard方法类似于反距离权重插值法,但它还校正站点方位的影响,且不需要提前设定初始值,是一种相对简单且有效的空间插值方法。
降水量受地形影响大,目前国际上还没有一种非常好的方法来订正地形对降水量的影响。为了进一步考虑地形影响,引入了国际上公认的质量最好的气候数据集PRISM (Parameter-elevation Regressions on Independent Slopes Model)数据。该数据通过建立点雨量观测值与局地海拔高度的经验关系进而生成了考虑地形影响的气候标准值,被共认为是至今质量最好的气候数据集(http://www.prism.oregonstate.edu/)。在定义中国区域的PRISM数据时,共利用了2600多个台站的30年标准值。目前得到的PRISM数据的空间分辨率为0.05°。
进一步定义Shepard插值得到的背景场与对应日期500米分辨率PRISM数据的比例系数,并将此系数与Shepard插值得到的背景场相乘,得到经过PRISM订正后的日气候背景场。此时定义的日气候背景场在一定程度上考虑了地形影响。
为了减小由于降水量空间分布上不连续带来的插值误差,没有直接对降水量数据进行空间插值,而是先利用日气候分析值定义降水量的比值数据(如式8):
![]() (8)
(8)
即某日降水量的比值数据是站点观测的日降水量与对应网格、对应日期气候背景场的商。
某月的降水量分析数据是该月比值数据与对应月份、对应网格的气候分析值的乘积;同样,某日的降水量分析数据是该日比值数据与对应日期、对应网格的气候分析值的乘积,即:
降水量网格数据=对应网格的降水量比值分析值×某网格的降水量气候分析值
此时得到的是空间分辨率为0.05°×0.05°的降水量网格数据。因为地形对降水量的影响随海拔高度的变化非常显著,分辨率越高得到的网格数据越有利于提高地形校正效果。另外,如此高的分辨率也可以更好的满足用户对不同空间分辨率数据的需求,最后生成的0.5°×0.5°的产品是在此基础上空间重采样得到的。





